要求 メール本文から必要な情報を抜き出して欲しい
RPAには基幹システムから自動送信されたメールを受診し、その本文の内容から必要なデータを読み込み、チェックするロボットがあります。
今回の要求は、受信されてくるメールの中から、以下のような情報を読み込んで欲しいと仮定します。
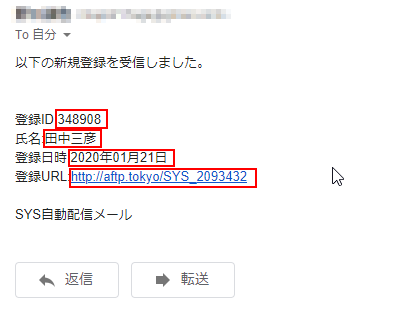
ワークフロー 概要
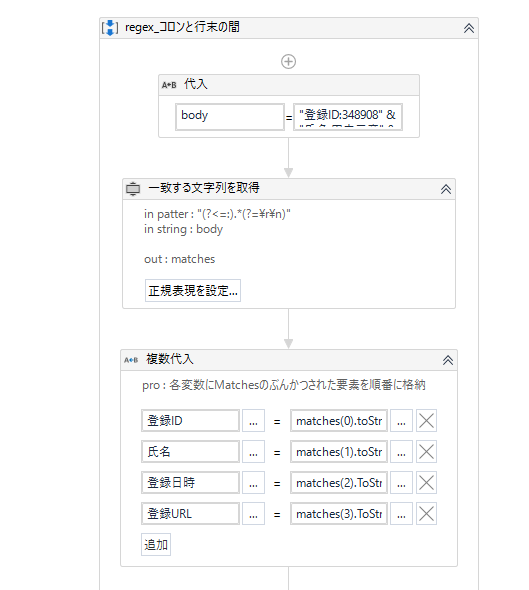
このようなワークフローを使って、実際に文字列を抽出してみたいと思います。ポイントは「正規表現」と「一致する文字列を取得」アクティビティです。
正規表現を使って抽出する
このやり方にはいろんな抽出方法があります。例えば改行を1行1行ずつ分割するSplitメソッドの方法です。
その中でも今回は正規表現を使った抽出方法を使っていきましょう。
この赤枠で囲まれた単語は、どのような法則性を持っているでしょうか、まず一つは、先頭にコロンがついていること、そしてもう一つは最後が行末であることです。

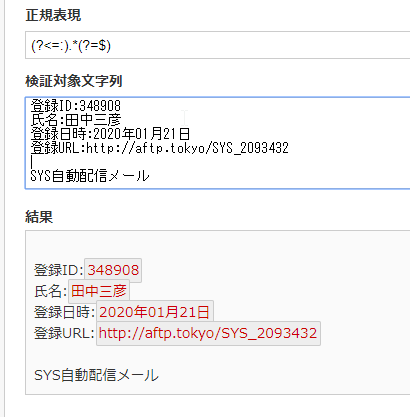
コロンと行末の間に挟まれている任意の文字を抽出する
(?<=:).*(?=\r\n)
この正規表現を説明すると、
?<=:
コロンが前に位置している
.*
任意の文字が存在している
?=\r\n
行末が最後に位置している
正規表現チェッカーのサイトはこちらからです。
ちょっと改行のところが上手く認識しなかったので、 ドルマークで対応しています。
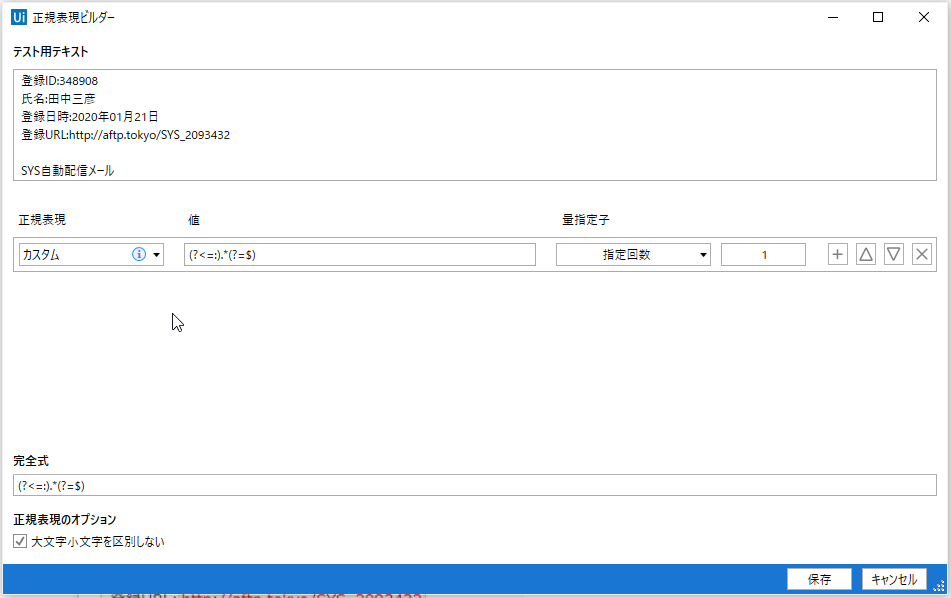
普通だったら正規表現ビルダーで見るんですけど、肯定否定の先読み後読みはちょっと対応していないみたいなので、正規表現チェッカーを使いました。
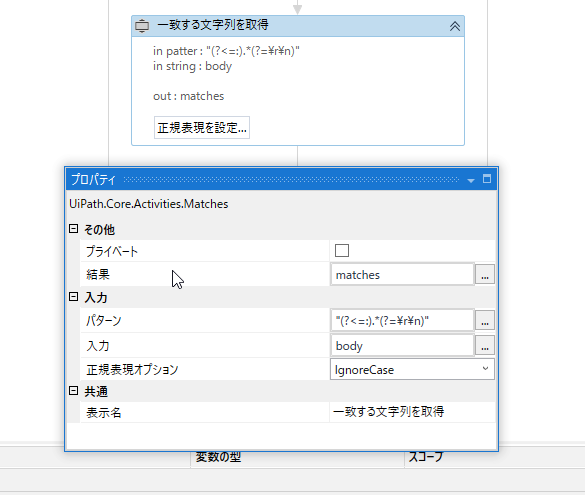
一致する文字列を変数 matches で返す
「一致する文字列」アクティビティは入力した文字列を正規表現で検索し、一致した値を変数「Matches」型で変えてしてくれます。
今回は、そのMatches型を「matches」として返してみます。
「一致する文字列を取得」アクティビティを通過した後、 ローカルパネルの値を参照してみます。「matches」の中に配列として4つ格納されました。
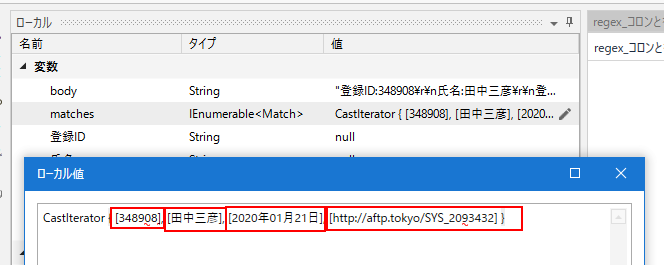
Matches型は「0」から順番に変数の値を返してくれます。
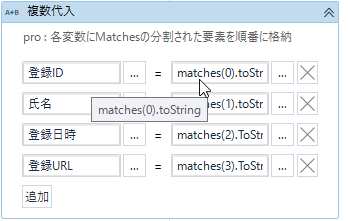
次の代入アクティビティで「登録ID」から順番にmatches(0).ToString で返していきます。
余談 これでも、まだエラーハンドリングが足りない。
おそらく、これだけでも十分に実装することは可能でしょう。しかし、もっとテストケースを入念に行う場合、本当に「登録ID – 氏名 – 登録日時 – 登録URL」の順番なのだろうか?というケースも考えるべきです。(もしくは、システム側に問い合わせて、本当にこの順番に変動はないのか問い合わせてみてもいいかもしれません)
一応、今回はここまで。
コメントは受け付けていません。